
Uncovering The Sound of Seattle Birds Through Neural Networks
Uncovering The Sound of Seattle Birds Through Neural Networks
Abstract:
The objective of this research is to classify the bird species based on their chirping sounds, which were recorded in mp3 format. The study utilizes data from the Birdcall competition dataset, sourced from the Xeno-Canto bird sound archive. I have worked on modeling a binary and multi-class classification problem to identify birds based on their chirping sounds. Neural Networks are being used in this case with different activation functions such as Relu, tanh, SoftMax, or Leaky Relu. I have also explored the effectiveness of using a CNN model and transfer learning from other paradigms to accurately classify the sounds of birds.
Introduction:
The analysis is divided into two categories: first involves binary class classification of two bird species, Amecro and Barswa, and the second involves extension into a multiclass classification problem to classify the sound of 12 birds from Seattle region. To carry out the research, the dataset from the Birdcall competition, which was sourced from the Xeno-Canto site. The objective of this study is to apply a methodology to classify birds based on their voice. The dataset is particularly interesting to work with as it contained varying lengths of audio recordings. Neural networks were employed to accurately classify the data into 12 distinct classes of bird chirping sound.
Theoretical Background:
A neural network is a machine learning model based on the structure and function of the human brain. It is intended to detect patterns in data and forecast outcomes based on those patterns. A neural network is, at its heart, a collection of interconnected nodes, or “neurons,” that process information in a layered structure. Each neuron receives information from other neurons, analyzes it, and then passes the result on to the next layer of neurons.
The input layer is the first layer of neurons in a neural network, and it receives raw data. The final layer of neurons is known as the output layer, and it is responsible for making the final predictions. The intermediate levels are known as hidden layers, and they perform intermediary calculations. A neural network adjusts the weights between neurons during training to increase its prediction accuracy. The network is fed a set of labeled training data, and an optimization method is used to update the weights such that the network’s predictions are as close to the true labels as possible.
Consider the neural network illustrated in Figure 1 as an example. It consists of three layers: an input layer, a hidden layer, and an output layer. The input layer comprises nodes representing four features, namely x1, x2, x3, and x4. Additionally, there are five activation functions denoted as A1, A2, A3, A4, and A5. These activation functions can be selected from a range of options such as Relu, tanh, sigmoid, softmax, and others. The choice of activation function depends on the specific objectives of the model and the performance characteristics of each function. Careful consideration is necessary to determine the most suitable activation functions for the desired outcomes. 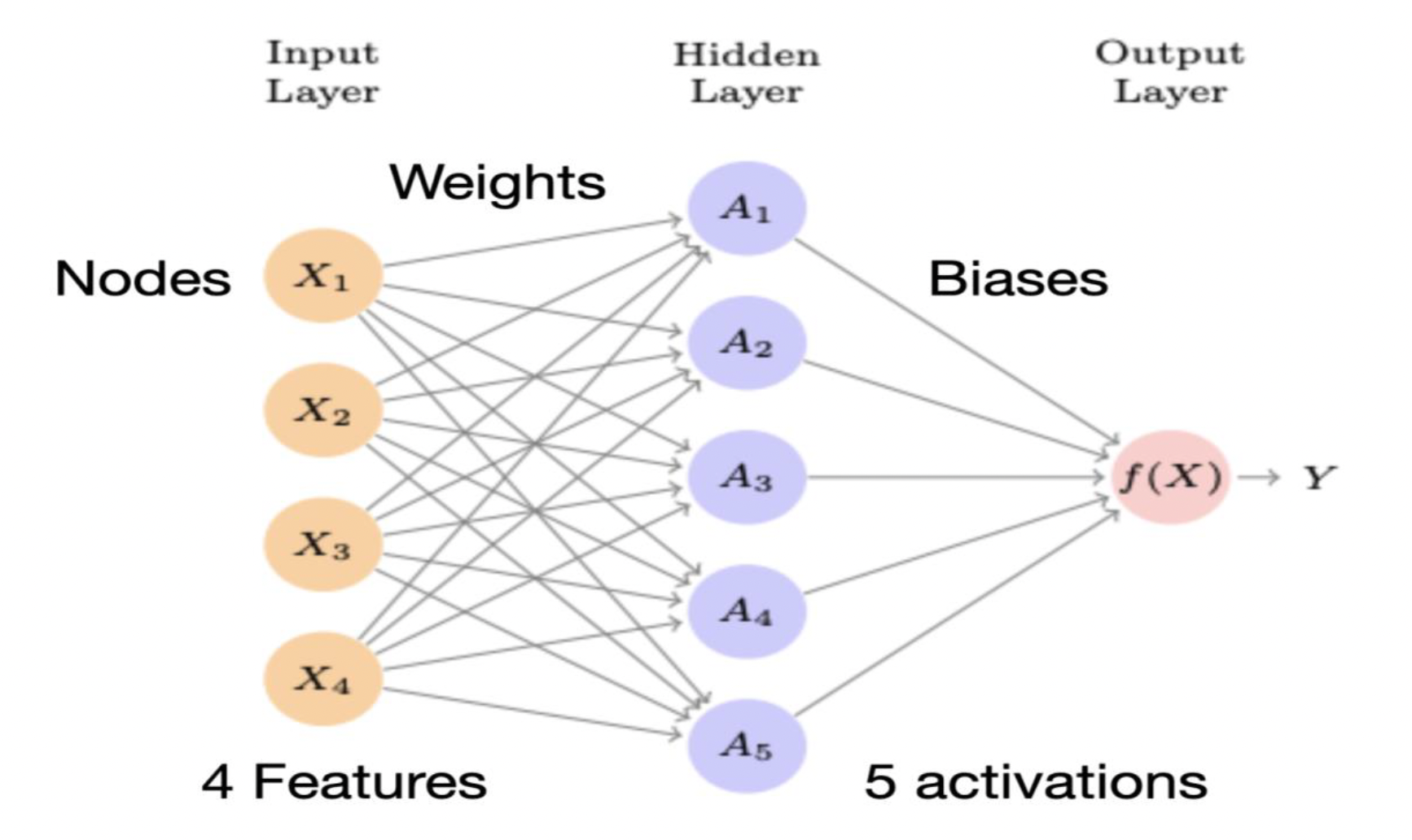 Figure 1: Neural Network Architecture with Input, Hidden, and Output Layers
Figure 1: Neural Network Architecture with Input, Hidden, and Output Layers
For instance, the Rectified Linear Unit (ReLU) activation function is a popular non-linear activation function used in neural networks. It is defined as:
f(x) = max (0, x); where x is the input to the function.
ReLU is a piecewise linear function that outputs the input if it is positive, and outputs 0 if it is negative. The main advantage of ReLU over other activation functions is that it is computationally efficient and easy to implement. One potential drawback of ReLU is that it can lead to dead neurons, where the neuron always outputs 0 for all inputs. This can occur if the weights are initialized in such a way that the neuron always outputs negative values. One way to mitigate this problem is to use a variant of ReLU called Leaky ReLU, which allows a small negative slope for negative inputs to prevent the neuron from becoming completely inactive.
Neural networks have been applied to a wide range of tasks, including image recognition, natural language processing, and speech recognition. They have proven to be very effective at solving complex problems that are difficult to solve with traditional algorithms. However, they can also be computationally expensive and require large amounts of data to train effectively.
In the training process of a neural network, two key components are the optimizer and the loss function. The optimizer determines how the network’s weights and biases are updated based on the computed gradients of the loss function. It aims to minimize the loss and guide the network towards better performance. There are various types of optimizers available, such as Stochastic Gradient Descent (SGD), Adam, RMSprop, and Adagrad, each with its own characteristics and update rules.
The loss function quantifies the discrepancy between the predicted output of the neural network and the true output. It measures how well the network is performing on a given task. Different types of tasks, such as binary classification, multi-class classification, or regression, require different loss functions. For example: the binary cross-entropy is suitable for binary classification, categorical cross-entropy for multi-class classification, and mean squared error (MSE) for regression.
Convolutional Neural Networks (CNNs) are a type of deep learning model commonly used in computer vision tasks such as image recognition and classification. CNNs are designed to automatically learn and extract meaningful features from images, making them well-suited for tasks that involve large amounts of visual data.
At a high level, a CNN consists of a series of layers that transform an input image into an output prediction. The first layer typically performs a convolution operation that applies a set of filters to the input image, extracting features such as edges and corners. Subsequent layers may perform pooling operations to down sample the image and reduce its size, followed by additional convolution layers to extract higher-level features. Finally, the output layer produces a prediction based on the features extracted from the input image.
One of the key benefits of CNNs is their ability to learn features automatically, without the need for manual feature extraction. This makes them highly adaptable to a wide range of tasks, from basic image recognition to more complex tasks such as object detection and segmentation. Additionally, CNNs can be trained on large datasets, allowing them to learn highly accurate representations of complex visual patterns.
Methodology:
This research aimed to classify bird data into multiple species, which presented a significant challenge in terms of managing and processing the sound dataset. The methodology for processing the sound clips to extract bird calls of a specific species involves several steps. Firstly, the sound clip is subsampled to half its original sample rate, resulting in a new sample rate of 22050 Hz. This step is performed to reduce the computational complexity of subsequent processing steps. Next, the “loud” parts of the sound clip are identified, specifically those that are greater than 0.5 seconds in duration. From these identified sections, 2-second windows of sound are selected where a bird call is detected. These windows are then used to extract the relevant bird call data. To further analyze the bird calls, a spectrogram is produced for each 2-second window. The spectrogram provides a visual representation of the sound in terms of its frequency and intensity over time, resulting in a 343 (time) x 256 (frequency) “image” of the bird call.
All bird calls for all clips in each species are saved individually. Due to variations in the number of birds calls in each clip, this results in an uneven number of samples in each species. However, this approach enables the subsequent machine learning model to effectively learn and classify bird calls based on their species-specific features. The objective of this study was to classify bird data into multiple species, with a specific focus on binary classification of Amecro and Barswa using a dataset comprising 803 recordings. To facilitate faster convergence, the standard scaler method was applied to the entire dataset to perform data scaling. The dataset was then trained using various neural networks with multiple hidden layers, and the performance of each model was recorded. Additionally, the data was transformed into matrix format to enable the application of a CNN model. However, the CNN models did not yield satisfactory results, as the model started overfitting soon.
To train the model, we compiled it with the Adam optimizer and used the binary cross-entropy loss function. We evaluated the model’s performance using the accuracy metric. During training, we conducted 10 epochs with a batch size of 32. The model achieved a validation accuracy of 47.83%. Although the results were promising, there is potential for further optimization to enhance its performance in classifying the Amecro and Barswa species.
In addition to the other models used for voice recording classification, I implemented a grid search method to identify the optimal hyperparameters for the neural network model. The objective was to train the model using a designated set of training data, enabling it to learn the underlying patterns and relationships between the input features and output labels. The aim was to optimize the performance of the neural network by determining the best combination of hyperparameters, including the number of layers, the number of neurons within each layer, the activation function, the batch size, and the number of epochs.
The layers parameter played a crucial role in defining the architecture of the neural network. It specified the number of layers and the number of neurons in each layer. This was achieved by utilizing a list of lists, where each inner list represented a layer and the number of neurons in that specific layer. For instance, [20] denoted a single hidden layer comprising 20 neurons, [40, 20] represented two hidden layers with 40 neurons in the first layer and 20 neurons in the second layer, while [45, 30, 15] indicated three hidden layers with 45 neurons in the first layer, 30 neurons in the second layer, and 15 neurons in the third layer.
The activations parameter allowed for the specification of the activation function to be used in each layer of the neural network. Various activation functions were tested such as sigmoid, relu, leaky_relu, tanh, and softmax. The inclusion of these activation functions introduced non-linearity, enabling the neural network to effectively learn intricate relationships between the input features and the output labels.
The batch size parameter determined the number of samples processed in each training iteration. Larger batch sizes could potentially expedite convergence, albeit at the cost of increased memory requirements. On the other hand, the epochs parameter determined the number of times the training data was processed by the neural network. Each epoch consisted of multiple iterations, during which the model updated its weights based on the discrepancy between the predicted output and the actual output.
To evaluate the performance of different hyperparameter combinations, the GridSearchCV function was employed. It facilitated a comprehensive grid search, systematically exploring various hyperparameter configurations and assessing their performance using cross-validation. Ultimately, the best combination of hyperparameters was selected based on the highest cross-validation score. The resulting model could then be utilized to make predictions on new data. We can see from the Table1 that the best model is LeakyRelu with 54% cross validation error. We can use this model to segregate the Amecro and Barswa species. When faced with a multi-class classification problem involving 12 birds from the Seattle region, the task of data segregation proved challenging due to the less volume of recordings. To expand the dataset, data augmentation techniques such as rotation of features, width shift, and horizontal scaling were employed. Various neural network models, including CNN and the ImageNet model, were utilized to classify the datasets. However, the ImageNet model exhibited overfitting and poor accuracy. To improve performance, dropout and batch normalization layers were incorporated into the neural network.
In the case of the multiclass classification problem, a neural network model was developed using a pre-trained Xception architecture, which is a powerful deep learning model. This base model was initially trained on a large dataset called ImageNet. To adapt it to our specific task, the top layer of the model, responsible for classifying images into thousands of categories, was removed.
I then converted the audio sounds into a 3D matrix so that the CNN layer can work on it. The neural network takes images with a specific size of 147 pixels in height, 100 pixels in width, and 3 color channels (red, green, and blue) as input (audio recording reshaped as image). The images are fed into the model through an input layer. To process the input images effectively, additional layers were added to the model. First, a flatten layer was inserted to convert the output from the base model into a simplified format. This step is necessary to prepare the data for further processing.
To improve the model’s performance, batch normalization was applied. It helps normalize the data and make it easier for the model to learn and make accurate predictions. Several dense layers were then added, each consisting of interconnected neurons. These layers serve as the main processing units of the neural network. The first dense layer contains 32 neurons and uses the Rectified Linear Unit (ReLU) activation function, which helps the model learn complex patterns and relationships in the data. A dropout layer was included after the first dense layer to prevent overfitting, a phenomenon where the model becomes too specialized in the training data and performs poorly on new, unseen data.
To further enhance the model’s performance, additional dense layers with 64 and 128 neurons were added, using ReLU activation and dropout regularization. These layers enable the model to learn more intricate features and capture important characteristics of the input data.
The final layer of the model, called the output layer, is responsible for making predictions. It consists of a number of neurons equal to the number of classes in the dataset. In our case, since we are working with categorical data, the output layer uses the softmax activation function, which calculates the probabilities of each class and assigns the input image to the most probable category.
To train the model, an optimization algorithm called Adam was employed. It adjusts the model’s internal parameters to minimize the error between predicted and actual values. The categorical cross-entropy loss function was chosen to measure the dissimilarity between the predicted class probabilities and the true class labels. The model’s performance was evaluated using the accuracy metric, which indicates how well the model correctly predicts the class of the input images. I have also used early stopping and learning rate parameter so that we are not throttling the system performance if model is not improving after 1 epoch.
Computational Results:
Binary Classification: In order to classify the species of Amecro and Barswa, we utilized a neural network model.
| Activation Function | Hidden layers | Cross validation error | Accuracy rate |
|---|---|---|---|
| Sigmoid | 1 | 52% | 74% |
| 2 | 44% | 64% | |
| 3 | 47% | 72% | |
| Relu | 1 | 44% | 69 % |
| 2 | 47% | 79% | |
| 3 | 50% | 63% | |
| LeakyRelu | 1 | 50% | 64% |
| 2 | 54% | 74% | |
| 3 | 47% | 62% | |
| Tanh | 1 | 43% | 65% |
| 2 | 44% | 75% | |
| 3 | 50% | 63% | |
| Softmax | 1 | 45% | 63% |
| 2 | 48% | 75% |
Table 1: Cross validation Error and Accuracy for Multiple Hidden Layers and Activation Functions.
The model had an input dimension of 44100 and consisted of a single hidden layer with five neurons. The rectified linear unit (ReLU) activation function was used in the hidden layer. To improve the model’s generalization performance, we applied batch normalization and dropout regularization techniques. For binary classification, the output layer had a single neuron with the sigmoid activation function.
Upon evaluating the model’s performance across various activation functions and hidden layer configurations, we observed moderate results which you can see in Table 1. Through multiple iterations and assessments, we obtained the most favorable performance metrics. Specifically, the model achieved a cross-validation error of 52%, indicating the average performance between predicted and true labels during cross-validation. Furthermore, the model achieved an accuracy rate of 74% on the test data, reflecting the proportion of correctly classified instances.
These performance metrics were obtained when utilizing a single hidden layer and the sigmoid activation function. Although the results were moderate, they provided valuable insights into the model’s capability to differentiate between the Amecro and Barswa species based on their chirping sound characteristics. Further exploration and refinement of the model’s architecture and training process may lead to improved performance in the future.
Multi-Classification:
During computational experiments, the aim was to achieve accurate classification of audio recordings using a neural network architecture. However, the obtained results did not meet the expectations. The models experienced overfitting, which occurs when the model become overly specialized to the training data and struggle to generalize to unseen data.
This overfitting issue became evident with a low cross-validation accuracy of only 10%. Such a low accuracy indicates that the models faced challenges in accurately classifying instances in the validation set, resulting in poor performance. Despite efforts to fine-tune the models and optimize the training process, satisfactory results were not achieved.
To address the overfitting problem, alternative models and architectures were explored. However, these models encountered similar difficulties in effectively learning from the training dataset. Even with the implementation of augmentation techniques to increase training set size and introduce variability, the models continued to struggle in achieving good performance.
To enhance the models’ performance on this specific dataset, it became evident that a larger quantity of high-quality recordings for training was necessary. The limited amount of available data caused the models to quickly overfit, hindering their ability to generalize well to new instances. By incorporating a more extensive and diverse set of audio recordings during training, the models would have a better opportunity to capture underlying patterns and achieve higher accuracy.
It is crucial to acknowledge that the performance of neural networks is heavily reliant on the quality and quantity of available training data. With an expanded and more diverse dataset, future iterations of the models may overcome the overfitting issue and exhibit improved classification performance for audio recordings of bird species.
Discussion:
The Xeno Canto dataset offers a wealth of data that can be utilized to address numerous questions related to bird species. In our study, we focused specifically on segregating bird chirping audio recordings. Our findings provide valuable insights, demonstrating that it is indeed possible to differentiate between Amecro and Barswa recordings. However, our study also revealed the need for a larger quantity of recordings to effectively classify the data. Despite exploring various neural network models, we encountered challenges as the models tended to overfit quickly and did not perform satisfactorily.
It is important to acknowledge the limitations of our study. The data was collected in a cross-sectional manner, which restricts our ability to establish causal relationships. Additionally, the reliance on self-reported data posed challenges due to high correlation and subsequent loss of nearly 50% of the data. Furthermore, the limited number of available features and heavy dependence on the audio recordings posed additional constraints.
Future research could benefit from addressing these limitations by incorporating longitudinal data, exploring additional features, and implementing strategies to mitigate the impact of high correlation. This would enhance our understanding of bird species classification based on audio recordings and provide a more comprehensive analysis of the Xeno Canto dataset.
Conclusions:
In conclusion, this research aimed to classify bird data into multiple species, with a particular focus on segregating the Amecro and Barswa species. The methodology involved various steps, including subsampling the sound clips, identifying relevant sections with bird calls, extracting bird call data, and generating spectrograms for analysis. Despite encountering challenges such as limited dataset size and overfitting, the study provided valuable insights into the classification process.
The research employed different neural network models, including CNN and the ImageNet model, along with data augmentation techniques to enhance the dataset. However, the CNN models exhibited overfitting and poor accuracy, indicating the need for further improvements. This research contributed to the understanding of classifying bird species based on audio recordings. Despite the challenges faced, the findings provide insights for future enhancements and optimizations in the field of bird species classification using neural networks. With further improvements and expanded datasets, it is possible to achieve more accurate and reliable classification results, thereby contributing to avian research and conservation efforts.
References:
[1] Bird Competition data: Xeno Canto Bird Recordings (Extended A-M). Retrieved from https://www.kaggle.com/datasets/rohanrao/xeno-canto-bird-recordings-extended-a-m [2] Xeno-Canto. (n.d.). The world’s largest community-driven sound library of bird songs and calls. Retrieved from https://xeno-canto.org/.