
Unlocking Answers Across Multiple PDFs: The Langchain Q&A
This Python script utilizes various natural language processing and machine learning tools to create a conversational system for answering questions related to uploaded PDF documents. The system incorporates tools from the Langchain library to facilitate text processing, embeddings, and conversational chains.
Table of contents
Requirements
- Python (>=3.6)
- Streamlit
- PyPDF2
- langchain (Install via
pip install langchain) - dotenv
Usage
- Make sure you have the required packages installed:
```bash pip install streamlit PyPDF2 langchain python-dotenv openai
Clone or download the repository to your local machine.
Open a terminal or command prompt and navigate to the directory containing the downloaded files.
- Run the Python script:
```bash streamlit run app.py
The Streamlit web application will open in your browser, allowing you to interact with the PDF question and answer system.
Upload PDF files using the provided file uploader.
Ask questions related to the uploaded PDFs using the chat input field.
The system will generate responses based on the uploaded PDF content and the input questions.
Features
- Extracts text content from uploaded PDF documents.
- Splits the text into manageable chunks for processing.
- Generates vector embeddings using various embedding models.
- Utilizes conversational chains for answering user questions based on the uploaded content.
Configuration
The script uses the Langchain library, including components for text splitting, embeddings, and conversational chains. Ensure that you have the required dependencies installed.
The load_dotenv() function is used to load environment variables from a .env file. Make sure to create a .env file in the same directory as your script if necessary.
Output
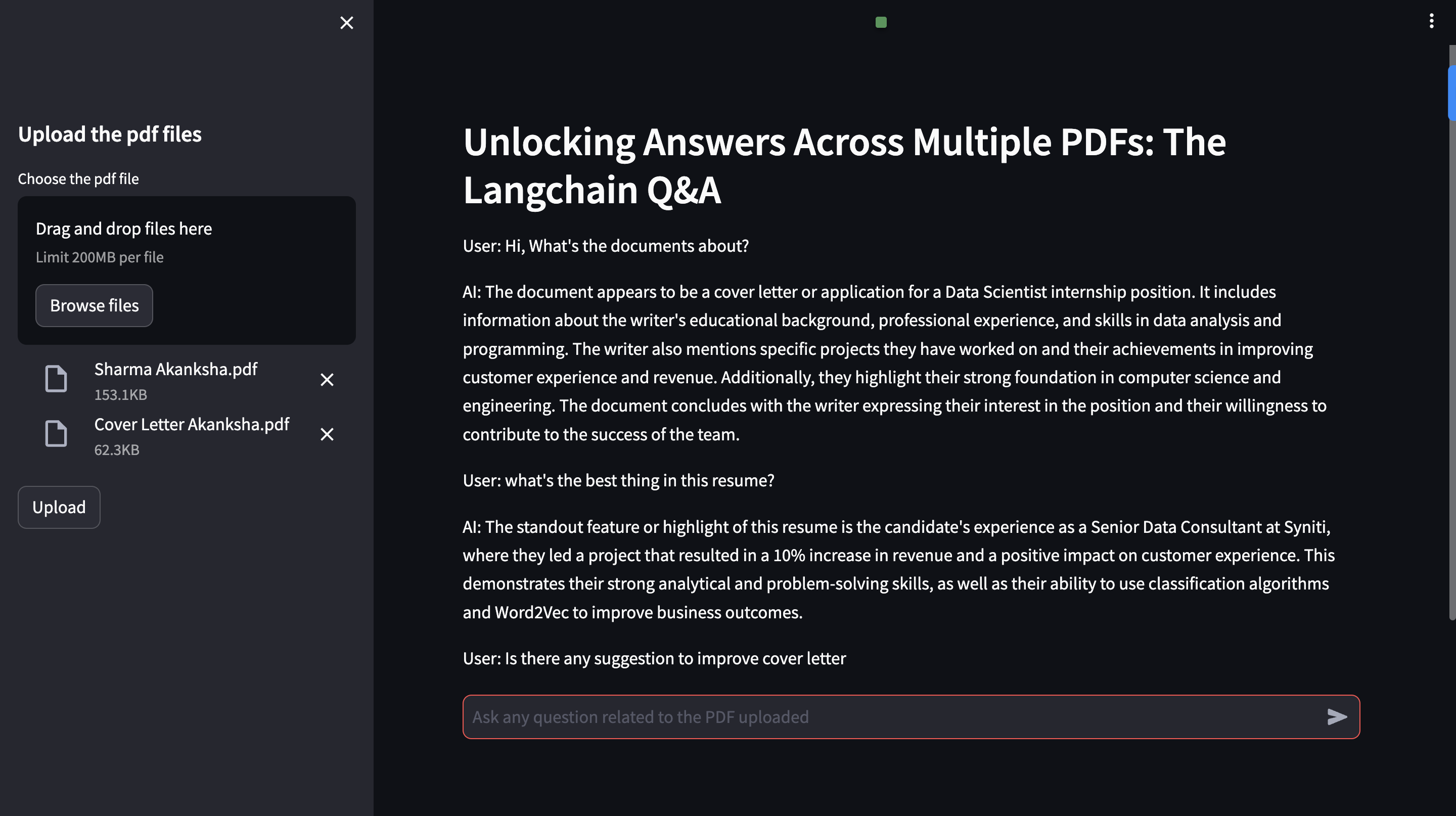
Here is an example screenshot of the Langchain PDF Question and Answer System in action:
Credits
This script was developed with the help of Langchain and various NLP tools. Special thanks to the open-source community for their contributions.