
Predicting Use of Harmful Substances Based on Parental Involvement, Religious Beliefs, and Education
Predicting Use of Harmful Substances Based on Parental Involvement, Religious Beliefs, and Education
Abstract:
It is fair to assume that the parental involvement, education, and religion beliefs affect the outcome on how child will perceive the use of harmful substance later in their life. This research, based on the National Survey on Drug Use and Health (NSDUH), aims to predict alcohol consumption among youth using behavioral factors and variables such as religious beliefs, parent-child relationship, academic factors, and participation in self-esteem and problem-solving groups were analyzed. The study highlights the importance of family and community support in reducing harmful behaviors among youth. Decision tree models were employed in this study to anticipate the behavior of young people in terms of consuming alcohol later in life. Additionally, the research expands to predicting the age at which young people will have their first encounter with alcohol.
Introduction:
Alcohol consumption among youth is a significant public health concern with potentially harmful consequences for both individuals and society. In this study, we aim to predict alcohol consumption among youth using data from the National Survey on Drug Use and Health (NSDUH). The NSDUH is an annual survey that collects data on substance use and related behaviors among individuals aged 12 years and older in the United States. Our attention is directed towards various factors such as religious convictions, the dynamic between parents and their children, academic performance, and engagement in groups aimed at improving self-esteem and problem-solving abilities. By analyzing these factors, we hope to identify potential risk and protective factors that could inform prevention and intervention efforts to reduce alcohol consumption among youth.
Theoretical Background:
Tree-based models use an algorithmic approach to split a data set based on certain conditions, making them suitable for regression and classification problems. The predictor variables are recursively divided into subsets to create the tree, with more significant variables at the top and insignificant ones discarded. A decision tree has two types of nodes: decision nodes, and leaf nodes. Decision nodes make choices and have multiple branches, while leaf nodes have no more branches and represent the output. The advantages of using tree-based models are easy interpretability, variable importance identification, and fast predictions. When decision trees are allowed to grow too large, they may become overfitted, resulting in less accurate predictions on new data. As a solution, pruned decision trees were developed to prevent overfitting.
A pruned decision tree is a decision tree that has undergone a process of reducing its size by removing branches that have little or no impact on the outcome variable, thereby enhancing its generalization and predictive performance. The basic idea behind pruning is to build a complete decision tree and then remove the branches that do not improve the model’s performance on the test data. Pruning can be performed in various ways, including cost-complexity pruning, reduced error pruning, and minimum description length pruning. In summary, pruned decision trees are a powerful and widely used technique in machine learning that helps to improve the predictive performance of decision trees, thereby enhancing the model’s accuracy and generalization.
While pruned decision trees are effective in improving the predictive performance of decision trees by reducing overfitting, ensemble methods are a popular machine learning technique that involve combining multiple models to produce a more accurate prediction than any individual model could achieve on its own. Two common types of ensemble methods are Bagging and Boosting.
Bagging, short for bootstrap aggregating, involves fitting multiple models on different subsets of a training dataset. The predictions from these models are then combined to produce a final prediction. The idea behind bagging is that by using different subsets of the training data to fit each model, the ensemble is able to capture different patterns in the data, leading to a more robust and accurate prediction.
Random Forest is an extension of bagging that is particularly effective for tree-based models. In a Random Forest, each individual tree randomly selects a subset of the predictors to split each node. By using different predictors for each tree, the ensemble is able to capture different aspects of the data, leading to a more accurate prediction.
Boosting is another ensemble method that involves fitting multiple models sequentially to correct errors made by previous models. The final prediction is a weighted sum of the individual model predictions, with more weight given to models that perform better on the training data. Boosting is particularly effective for improving the accuracy of weak models, such as decision trees.
In summary, ensemble methods like Bagging and Boosting are powerful techniques for improving the accuracy of machine learning models. Bagging improves the performance of models by fitting multiple models on different subsets of the training data and combining the predictions. Random Forest is a specific type of bagging that is particularly effective for tree-based models. Boosting improves the performance of weak models by fitting multiple models sequentially and weighting their predictions.
Methodology:
The aim of this research was to predict the use of alcohol and other harmful substances and to determine the age at which individuals are likely to start using them. The methodology involved a thorough analysis of the NSDUH dataset, with a focus on removing irrelevant variables and null values. To identify the correlation between alcohol consumption and other substances, variables with a strong correlation to alcohol consumption were removed.
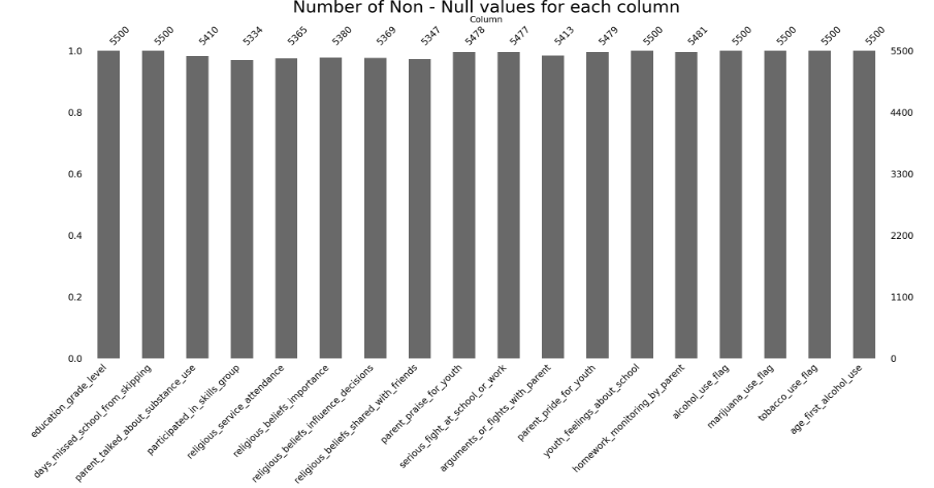
To better understand the impact of missing data on the dataset, we analyzed the pattern of missing data, as shown in Figure 1. We then used MICE to replace the null values in the dataset, ensuring that our analysis was based on complete data. Our methodology aimed to provide an accurate prediction of alcohol consumption and other substance use, considering all relevant factors and minimizing the impact of missing data on our analysis.
To accurately predict alcohol consumption, we employed decision tree models for classification tasks using a range of demographic and behavioral factors such as age, gender, race, education level, and family income as predictors. To evaluate the performance, we utilized cross-validation techniques. Later, we extended our model to multiclass classification to identify the usage of alcohol, marijuana, or tobacco. The multiclass classification model combined the flags for alcohol, tobacco, and marijuana use to create a single variable called substance use flag, which allowed us to analyze their impact on substance use habits.
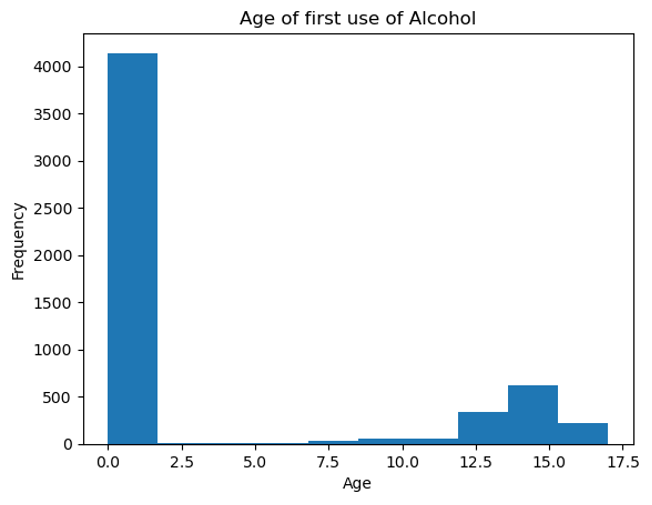
To broaden the scope of our research, we aimed to predict whether an individual will consume alcohol and the age at which they will begin doing so. To achieve this objective, we developed a regression model. Initially, we examined the data to identify any outliers, and we found that some individuals reported consuming alcohol before the age of 7, which is highly improbable. We resolved this issue by replacing such values with 7 as the age indicator when a person first tried drinking alcohol. Furthermore, we examined the distribution of the age at which youth reported their first alcohol consumption, which is presented in Figure 2. We observed that many teenagers tend to take their first sip at the age of 15, and there is a significant number of individuals who have not yet consumed alcohol. To test whether our regression model can accurately forecast this behavior, we will evaluate its performance. In summary, our methodology involves identifying outliers and addressing them, analyzing the distribution of age at which youth consume alcohol, testing our regression model’s accuracy, and evaluating its performance.
By using this methodology, we were able to accurately predict alcohol usage among youth and gain insights into the role of demographic and behavioral factors in predicting substance use. Our research findings have important implications for the development of interventions and policies aimed at preventing youth substance use.
Bottom of Form
Computational Results:
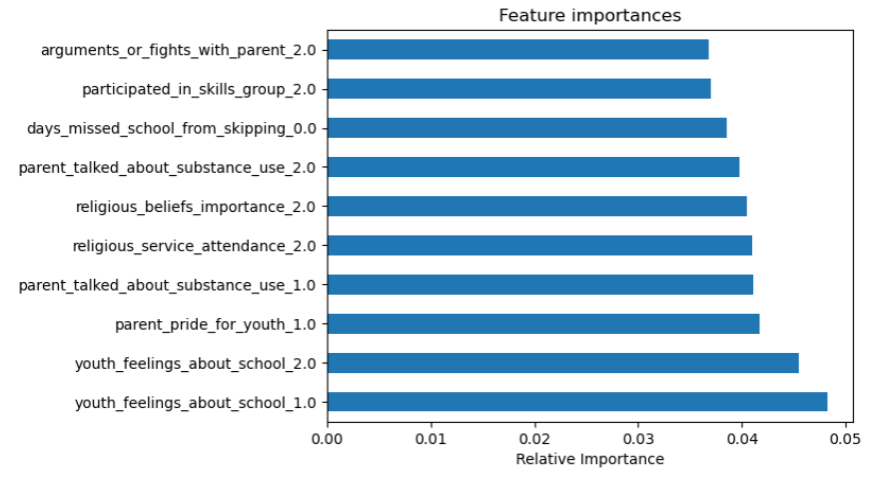
In a binary classification problem where the task was to predict whether youth would consume alcohol or not, the dataset was found to be imbalanced, with 4138 out of 5550 adult datapoints not consuming alcohol. To address this, we used stratified sampling and considered class imbalance while training various decision tree and ensemble models. Upon training the decision tree model, we discovered that the accuracy of the binary classification was highly dependent on the youth’s feelings about attending school, emphasizing the importance of education in predicting alcohol consumption. Moreover, we observed that parental communication about substance use, and the child’s accomplishments also had an impact on the decision. Interestingly, the number of school days missed had a relatively lesser impact on the prediction compared to other variables in the dataset. Figure 1 highlights the crucial features for predicting whether a person will consume alcohol or not.
We got the same accuracy with pruned tree as a normal decision tree with just one single node. It’s worth noting that we achieved a 75.2% accuracy on the test results when predicting whether a person will drink or not. Additionally, it’s intriguing to observe that we’re encountering the same level of error as the unpruned tree.
| Image 1 | Image 2 |
|---|---|
 | 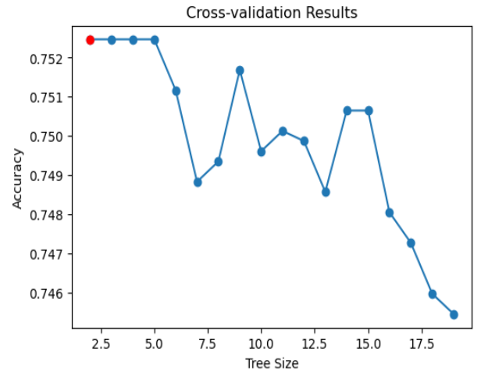 |
Multiclass classification: In the context of multiclass classification, our goal is to determine whether a person will use any form of substance. To achieve this, we have categorized the output into four distinct classes, as previously mentioned.
| Multi-class Classification | |
|---|---|
| Substance Use | Output Value |
| Alcohol | 1 |
| Marijuana | 2 |
| Tobacco | 3 |
| No Substance Use | 0 |
Table 1: Multiclass classification output
After attempting several methods, we discovered that the bagging model was the most effective for this dataset. However, if we had additional information about youth behavior, we could further enhance the accuracy of the model. This can be observed in the confusion matrix, which illustrates the model’s performance. It is worth noting that the model performs well in predicting instances where there is no substance use. The model is currently achieving an accuracy rate of 65%.
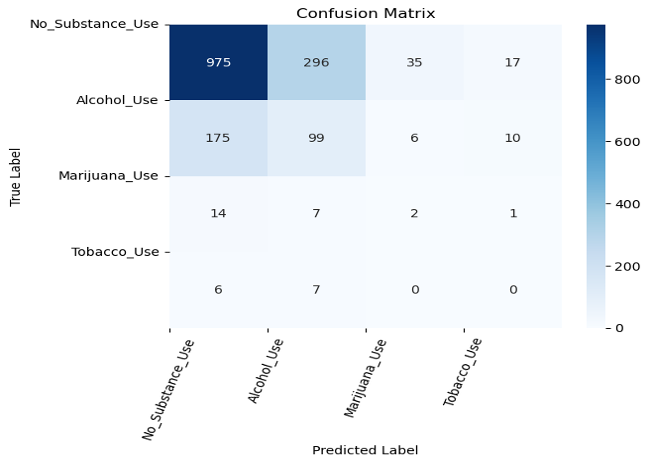
Regression model: In the context of a regression problem, we were trying to predict the age at which young people will try alcohol for the first time. To accomplish this, we used various models to predict the output. One of the methods we used was pruned decision tree to do regression analysis, which allowed us to predict the age of the first drink with an accuracy of approximately 96.84%, considering the limitations of the data we had.
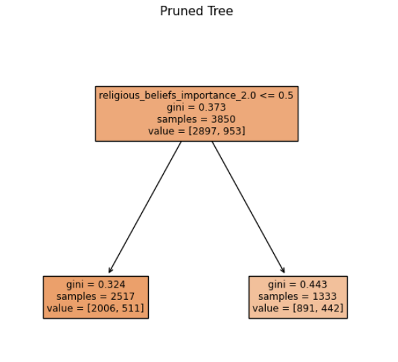
During our analysis, we found that the “alcohol use” flag in the pruned tree was a significant predictor of the age at which a person started drinking. This means that whether a person has used alcohol or not can have a significant impact on the age at which they try it for the first time. Additionally, we found that the occurrence of serious fights at school or work was the second most important predictor for determining the age of first drink. This suggests that such incidents can have a significant impact on a person’s behavior and mental health, potentially leading to long-term health concerns like depression.
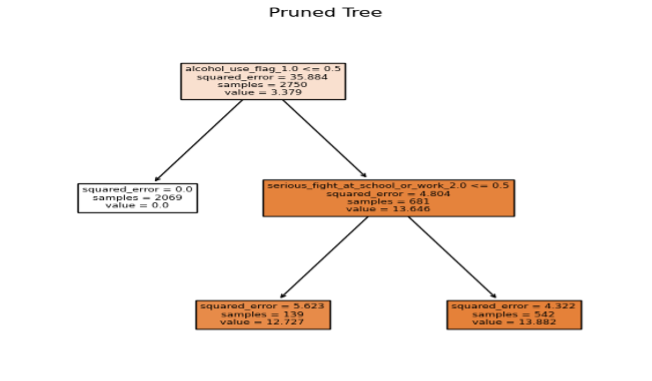
To visualize our findings, we created a decision tree, which is a tool used to predict outcomes based on different conditions. The tree starts with a condition about whether or not a person has used alcohol. If they have used it very little or not at all, the tree goes to the left and predicts a certain outcome. If they have used alcohol more than a little, the tree goes to the right and looks at whether or not they have been involved in a serious fight at school or work. Based on the different conditions, the tree predicts different outcomes, represented by numerical values.
Our findings were based on data from a sample of 2750 people, and the accuracy of the predictions varied depending on the conditions that applied to each group of people. Overall, our analysis sheds light on important factors that can impact the age at which young people try alcohol for the first time and highlights the importance of considering these factors in prevention and intervention strategies.
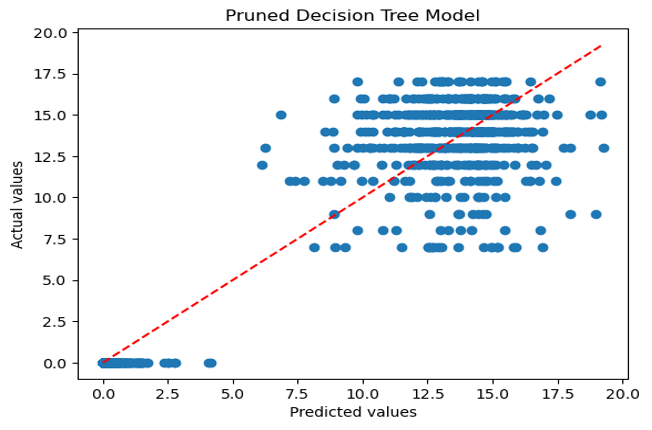
Looking at the pruned decision tree output model graph, we can observe that the predicted values are generally close to the actual values, indicating that our regression model performed well in predicting the age at which a person will try alcohol for the first time, given the limitations of the data.
Discussion:
It is worth noting that the NSDUH dataset includes a vast array of data that can be used to answer many more questions related to substance use and other topics. Our study’s specific focus on religious beliefs and school behavior was just one aspect of the available data. Nonetheless, our findings provide valuable insights into the potential risk and protective factors that can inform prevention and intervention efforts aimed at reducing substance use among youth. Our findings indicate that these factors significantly influence a person’s likelihood of consuming substances later in life. Therefore, it is essential to engage students in fostering positive relationships with the people in their lives, including parents and teachers, to reduce the risk of harmful behaviors.
The study aimed to predict alcohol consumption among youth using various behavioral factors and to identify potential risk and protective factors for informing prevention and intervention efforts. The findings showed that parental communication about substance use, academic accomplishments, and the child’s feelings about attending school were highly influential in predicting whether a person would consume alcohol or not. The decision tree model achieved an accuracy of 75.2% on test results, indicating its effectiveness in predicting alcohol consumption. Furthermore, the model’s accuracy was not compromised by pruning.
Regarding multiclass classification, the study aimed to determine whether a person would use any form of substance, including alcohol, tobacco, and marijuana. The analysis revealed that parental communication, academic performance, and participation in self-esteem and problem-solving groups were significant predictors of substance use.
However, the study had limitations such as the cross-sectional nature of the data, which limits the ability to infer causality, and self-reported data on substance use subject to social desirability bias, which could impact the accuracy of predictions. Additionally, the dataset’s sample size was relatively small, which may limit the generalizability of findings to the larger population.
In conclusion, the study provides valuable insights into potential risk and protective factors for reducing alcohol consumption among youth. The findings underscore the need for targeted interventions aimed at reducing substance use among youth and highlight the importance of education and family support in reducing harmful behaviors.
Conclusions:
Our study aimed to predict alcohol consumption using decision tree models and tree-based ensemble models such as Random Forest, Bagging, and Boosting. We utilized data from the NSDUH survey and found that the models were able to achieve impressive accuracies. For the binary classification problem, the decision tree after pruning yielded an accuracy of 75.09%. Furthermore, the Pruned Decision Tree model demonstrated an accuracy of 96%, using less than half the number of predictors.
These findings suggest that decision tree models and ensemble methods are effective tools for predicting if an individual will consume alcohol or not. They can also be utilized to determine the age at which a person is likely to try their first drink or whether a young person will try alcohol. The models’ performance is encouraging and highlights their potential in aiding early intervention strategies to prevent alcohol misuse.
Overall, our study contributes to the existing body of literature on the use of decision tree models and ensemble methods in predicting alcohol consumption. These tools offer a promising approach for identifying individuals who are at risk of alcohol misuse and providing appropriate interventions.
References:
Substance Abuse and Mental Health Services Administration. (2020). National Survey on Drug Use and Health (NSDUH) 2020. [Codebook]. Retrieved from https://www.datafiles.samhsa.gov/sites/default/files/field-uploads-protected/studies/NSDUH-2020/NSDUH-2020-datasets/NSDUH-2020-DS0001/NSDUH-2020-DS0001-info/NSDUH-2020-DS0001-info-codebook.pdf